Product Sentiment Analysis
Overview
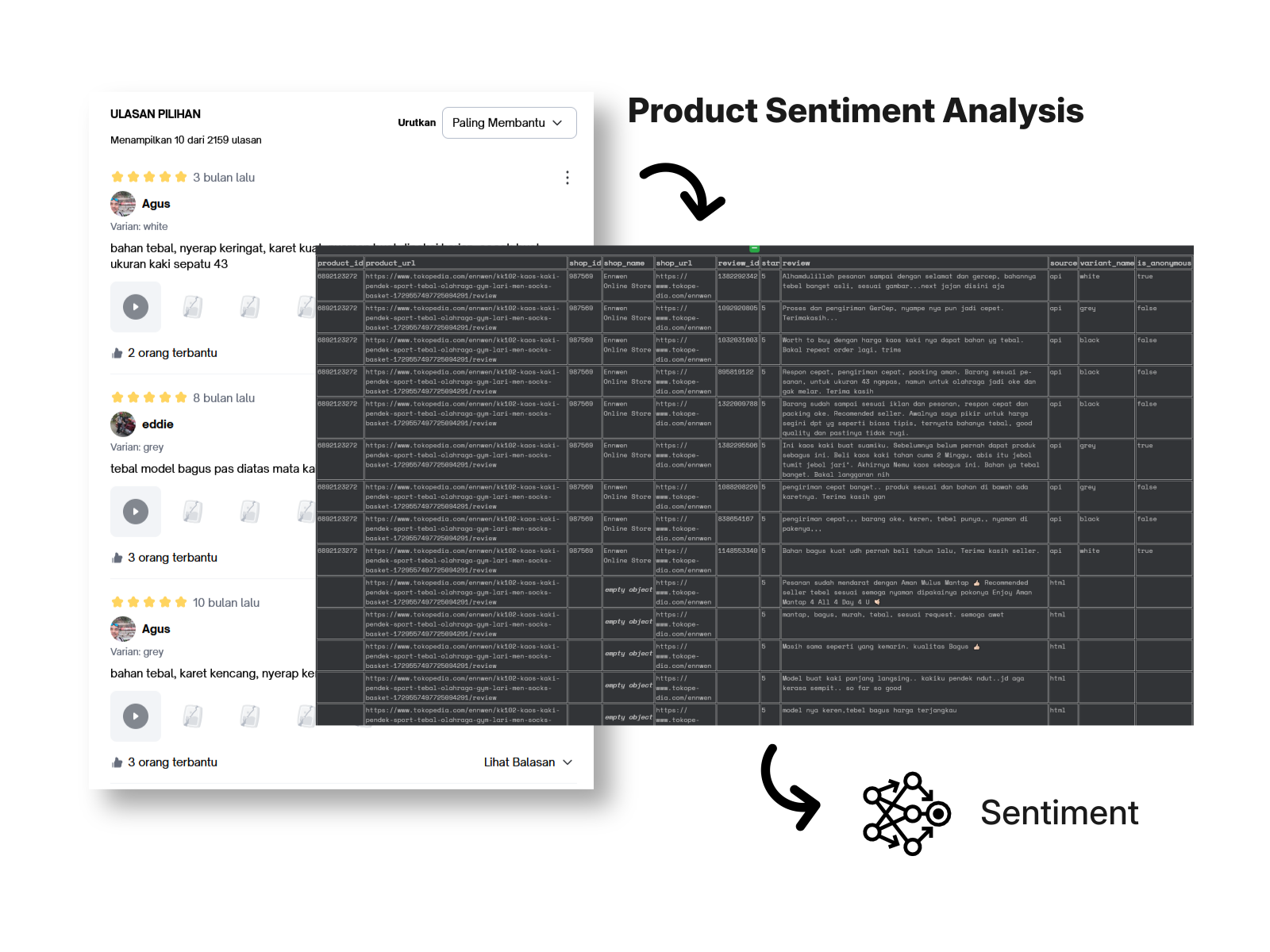
For this project, I developed a robust data collection pipeline to gather product reviews from major Indonesian e-commerce platform Tokopedia. The goal was to build a dataset suitable for sentiment analysis to understand consumer opinions and trends in Indonesia’s dynamic online retail space.
Challenges
Scraping product reviews from Tokopedia presented several obstacles:
- Anti-Scraping Measures: Tokopedia uses sophisticated anti-bot mechanisms, including JavaScript rendering and dynamic content loading, making traditional scraping unreliable.
- Dynamic Content: Reviews and product information are loaded asynchronously, requiring browser automation and dynamic action chains.
- Pagination and Data Volume: Reviews are spread across many pages, and each product may have hundreds or thousands of reviews.
- Localization: Website structure and review elements use Indonesian language and region-specific UI, requiring careful parsing.
Solution
To overcome these challenges, I engineered a custom Scrapy spider with the following features:
-
Automated Dynamic Browsing: Leveraged the Zyte (formerly Scrapinghub) API, enabling headless browser control and JavaScript execution. This allowed the spider to wait for dynamic elements, click through modals, and trigger review loads as a human user would.
-
Action Chains: The spider scripts precise sequences—including waiting for selectors, clicking navigation or modal buttons, and scrolling—ensuring all content loads properly before extraction.
-
Review Pagination: To maximize data collection, the spider automatically paginates through reviews by repeatedly clicking the “next page” button, capturing up to 99 pages of reviews per product.
-
Network Capture for API Data: Instead of relying only on HTML parsing, the spider inspects network traffic for hidden API responses (
/productReviewList). This allows extraction of structured, clean data directly from the backend, including product IDs, shop info, review text, ratings, and metadata such as reviewer anonymity and review variants. -
Fallback to HTML Parsing: If API data is unavailable, the spider gracefully falls back to parsing reviews from the rendered HTML, ensuring no data is missed.
-
Extensible Category Coverage: The spider iterates through dozens of popular product categories, scraping reviews across a wide spectrum of Indonesian consumer goods.
Example Workflow
- The spider visits a Tokopedia category page.
- It loads and interacts with the page as a browser would, handling pop-ups and lazy-loaded content.
- For each product, it modifies the URL to access the review section.
- It navigates through the reviews, triggering network requests and extracting both API and HTML-based review data.
- The extracted data includes fields like product/shop ID, review content, star rating, and reviewer characteristics, making it ideal for downstream sentiment analysis.
Impact
This pipeline enabled the creation of a rich, labeled dataset of over 100,000 Indonesian e-commerce product reviews. By overcoming common web scraping hurdles, it provided the high-quality data necessary for a subsequent sentiment analysis task. The well-structured and voluminous dataset was then used to train and evaluate various machine learning models, driving actionable insights into Indonesian consumer sentiment.
Downstream Task: Sentiment Analysis
With the dataset secured, a sentiment analysis model was developed to classify reviews into positive, neutral, or negative categories. The process involved:
- Text Preprocessing: A comprehensive pipeline was built to clean the raw review text. This included case folding, handling emojis by converting them to text, normalizing slang and abbreviations (e.g.,
ygtoyang), stemming Indonesian words using Sastrawi, and removing stopwords. - Feature Extraction: To convert text into numerical features, pre-trained Indonesian FastText word embeddings were used. An experiment was conducted comparing two approaches: simple averaging of word vectors and a weighted average using TF-IDF scores to give more importance to meaningful words.
- Model Training & Evaluation: Several models were trained and evaluated, including XGBoost and a custom-built deep learning network. The models were trained to predict sentiment based on the processed review text. The deep learning model using FastText embeddings proved to be the most effective, achieving a high F1-score in classifying consumer sentiment.
This end-to-end project demonstrates the full lifecycle of a data science task, from robust data acquisition in a challenging environment to the development and evaluation of a predictive model.
Key Takeaways
- Advanced web scraping requires a mix of browser automation, API inspection, and fallback strategies.
- Handling anti-scraping and dynamic content is crucial for modern e-commerce data extraction.
- A high-quality, well-structured dataset is the foundation for any successful machine learning model.
- Combining structured API data with HTML scraping ensures completeness and reliability.